Rigging with RAG: How to make a retrieval augmented chatbot with Vertex AI?
Retrieval-Augmented Generation (RAG) integrates external data with LLMs to improve responses. Learn to build a RAG-powered search with Vertex AI Search, Text Embeddings and Google Cloud Storage.

The chatbot market is growing at a pace that’s hard to ignore. North America’s chatbot sector is projected to expand at a jaw-dropping 23.3% CAGR by 2030. But that’s just the start. Enterprises are set to spend a whopping $1.3 trillion on consumer-facing AI tools by 2032, according to Freshworks. And here’s the kicker: 80% of business leaders believe that the best return on their generative AI investment will come from automating customer service and knowledge management.
Sounds like chatbots are the real MVPs, right?
They’re not just great for improving efficiency—they’re also fantastic for boosting the bottom line. Given all this, it makes perfect sense to dive into how we can build contextual chatbots that actually get what users need, and make a real impact. After all, with the way things are going, knowing how to build these bots might soon be a must-have skill for businesses looking to stay competitive.
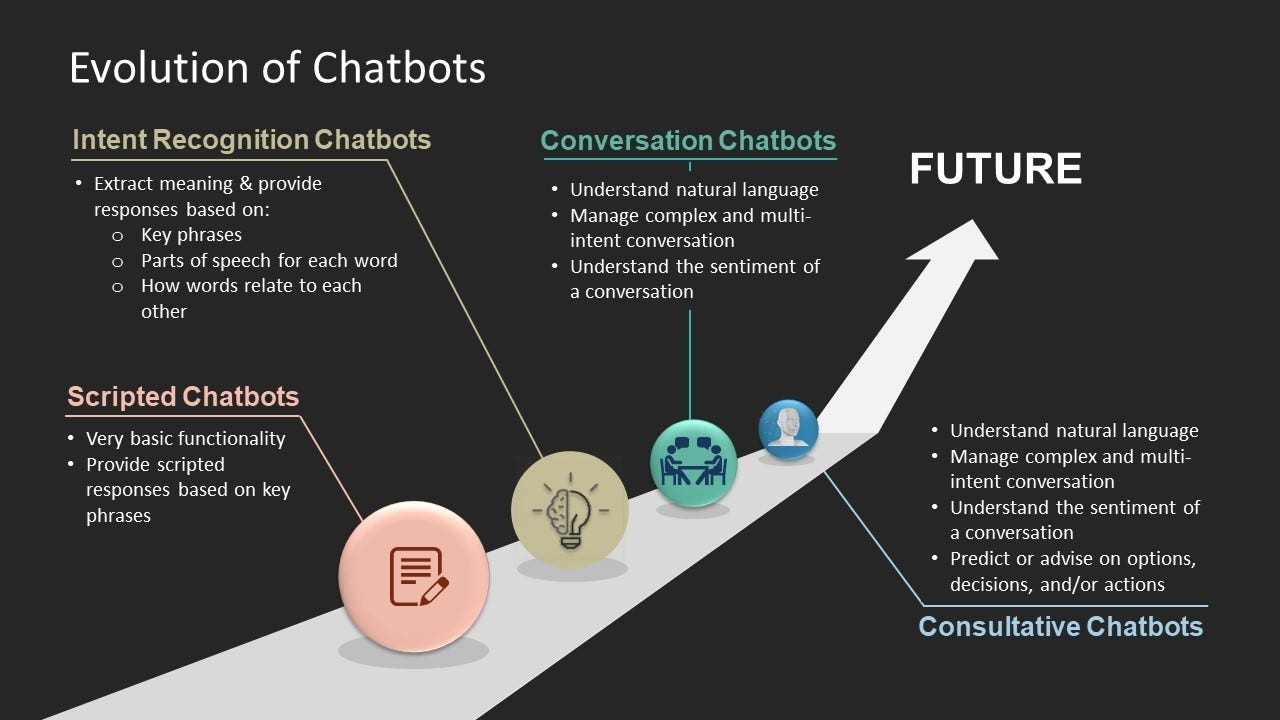
Evolution of chatbots
Chatbots have come a long way since their humble beginnings.
At first, we had scripted chatbots—basic if-else flows that would answer questions like a robot (because, well, they were).
Then came intent recognition chatbots, which could recognize keywords and send users down the right path.
To top that, we got to conversation chatbots: these bots could finally understand natural language, picking up on tone and sentiment. They could handle natural language and handle multi-turn conversations.
And finally, we’ve reached the next level of evolution in consultative chatbots—these bots do everything conversation chatbots do, but they also understand context and provide advice, and delivering complex insights, reviewing multiple knowledge and information sources. It’s a whole new level of chatbot sophistication.
But how do these chatbots get access to knowledge databases?
RAG, or Retrieval Augmented Generation
At its core, a standard query to a large language model (LLM) simply generates a response based on the model’s internal training data. While this is great for many use cases, it has one major drawback: it doesn’t have access to real-time or external data.
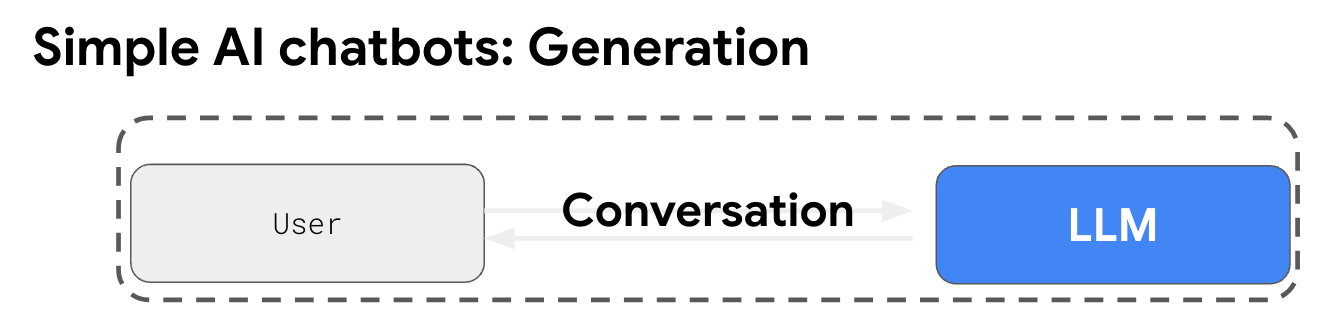
This is where Retrieval-Augmented Generation (RAG) comes in. Think of RAG as an added layer around the LLM. With RAG, a query first pulls in contextual data from external sources, such as databases or search engines. Then, both the query and the fetched data are passed into the LLM together. The result? A more informed, dynamic, and contextually accurate response, making the whole process much more powerful. It’s like giving the LLM access to a knowledge base, so it can actually know what’s going on in the world beyond its training.
So, how exactly is this data layer around a query built? There are several ways to approach it, each with its own strengths and trade-offs. One common, fast becoming popular method the Vector Space Model, where documents and queries are represented as vectors in a high-dimensional space, and measures like cosine similarity are used to determine which documents are most relevant to the query.
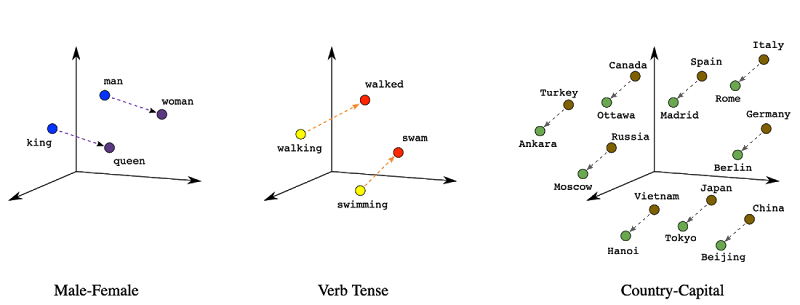
Generating a Vector Space Model is like mapping terms onto an n-dimensional vector space, where each term or document is represented as a point in that space. The dimensions correspond to the features or characteristics of the terms—think of them as the “ingredients” that define what a term is about. Once mapped, the similarity between documents or queries can be measured by how close their vectors are in this space. For example, cosine similarity measures the angle between two vectors, giving us an idea of how semantically similar two terms or documents are. This approach allows for highly flexible and scalable retrieval, where even subtle nuances in meaning can be captured by the relative positioning of terms in the space. Essentially, it transforms text into a mathematical representation that can be processed, compared, and analyzed for relevance.
Creating a vector space model can be considered a form of indexing—but with a more specialized twist. In traditional information retrieval systems, indexing typically refers to the process of creating an inverted index, which maps terms to the documents they appear in. However, in the context of a Vector Space Model, indexing involves mapping terms or documents into a high-dimensional vector space, where each term is represented by a vector, and the relationships between terms are encoded in that space.
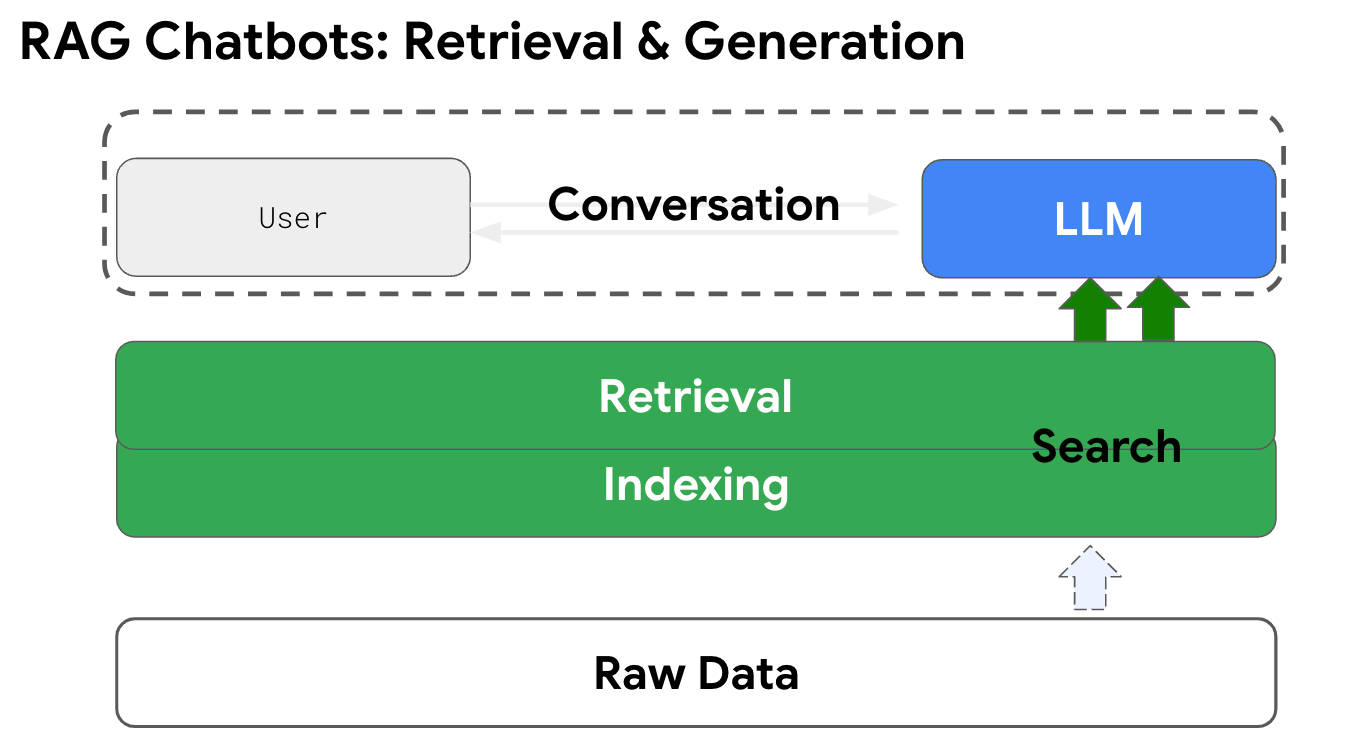
This type of indexing allows for more complex and semantic search capabilities, like measuring the similarity between queries and documents based on vector closeness, rather than just term matching. So, while the term "indexing" may have a broader, more traditional meaning in information retrieval, in this case, it refers to the process of building a mathematical model (the vector space) that enables more advanced search and retrieval techniques.
So now that we have our retrieval mechanism, let’s build our RAG-powered search with Vertex AI!
RAG-powered search with Vertex AI
Building a RAG-powered search with Vertex AI involves 4 key steps
Gather documents or knowledge base.
Create text embeddings from knowledge case.
Create Search Index using Vertex AI.
Create query embeddings to retrieve closest matches and add to prompt that is sent to the LLM for a response.
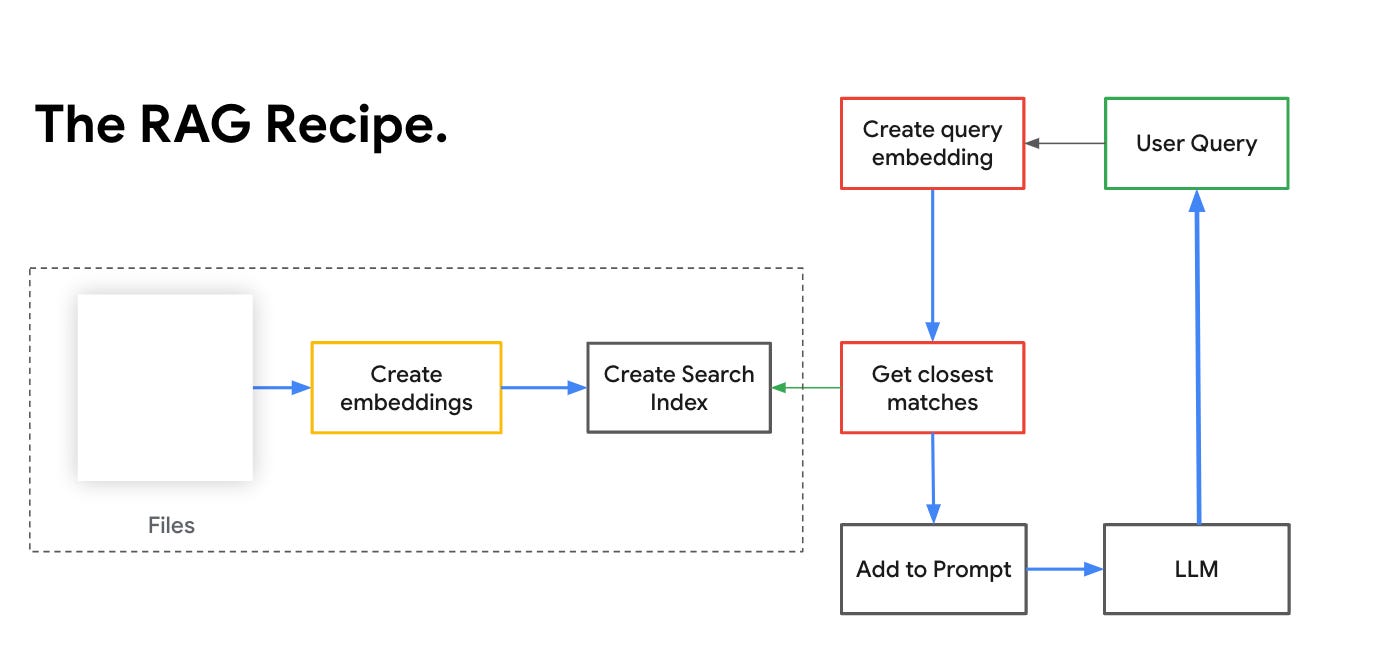
Gather data into Google Cloud Storage
The first step is collecting and storing the relevant data. This could be documents, product details, knowledge articles—whatever data your chatbot will need to pull from. By storing this data in Google Cloud Storage (or any cloud storage), you make it easily accessible for further processing.
Create Text Embeddings
Once your data is stored, the next step is to convert this raw text into embeddings. This involves using a model to represent text as vectors in a high-dimensional space. These embeddings capture the semantic meaning of the text, allowing you to measure how similar or relevant different pieces of content are to a given query.
For e.g, load your file and convert each sentence to embeddings, using the code below,
def load_file(sentence_file_path):
data = []
storage_client = storage.Client(project)
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(sentence_file_path)
str_json = blob.download_as_text()
file = str_json.splitlines()
for line in file:
entry = json.loads(line)
data.append(entry)
return datadef generate_text_embeddings(sentences):
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
embeddings = model.get_embeddings(sentences)
vectors = [embedding.values for embedding in embeddings]
return vectorsYou can then store the embeddings themselves in Google Cloud Storage.
Create a Vector Search using the Embeddings
With the embeddings in hand, you can now set up a Vector Saerch. This allows you to search for documents by comparing the query's embedding against the embeddings of all stored documents. Vertex AI's Vector Search (previously known as matching engine) provides an easy to use no-code to index the embeddings and perform fast, approximate nearest neighbour search to retrieve the most relevant documents. Bonus: You can use embeddings stored directly in Google Cloud Storage!
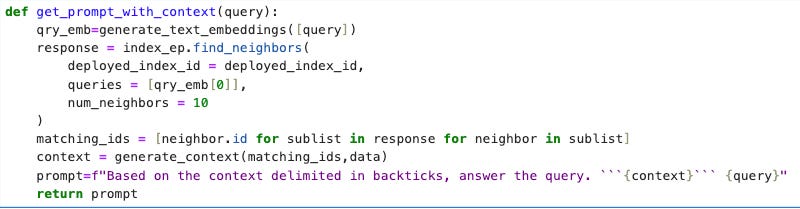
Create a Prompt with Context
Once you’ve identified the most relevant documents, it’s time to feed this information into your model. You’ll create a prompt that combines the original query with the contextual data pulled from the search results. This context helps the model generate a more informed and accurate response, effectively augmenting the LLM’s output with real-time, domain-specific data.
By combining these steps, RAG-powered search with Vertex AI can provide powerful, contextually aware responses, bringing together the best of both generative AI and external data retrieval.
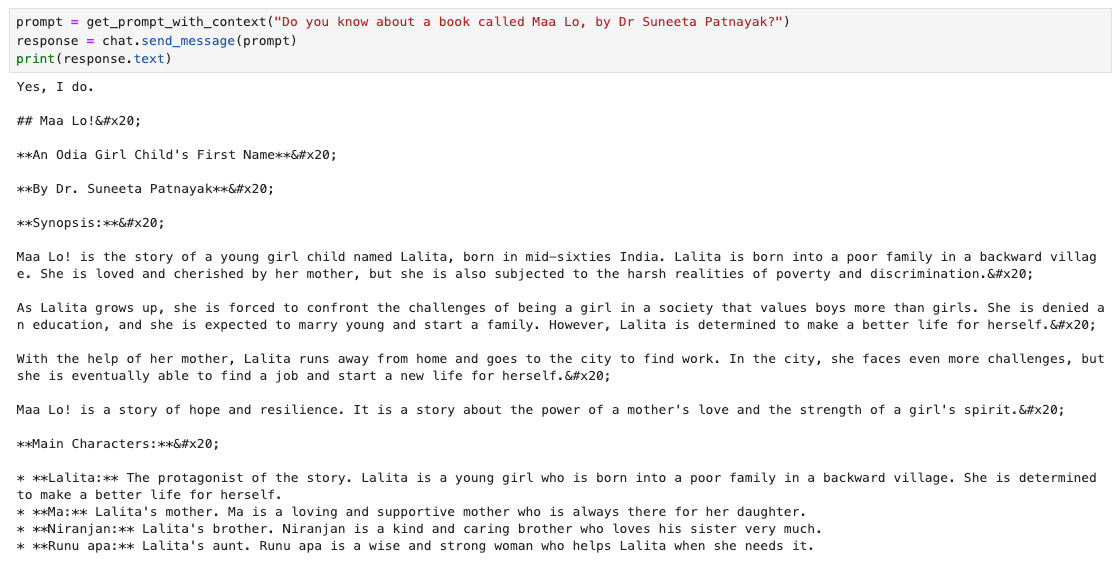
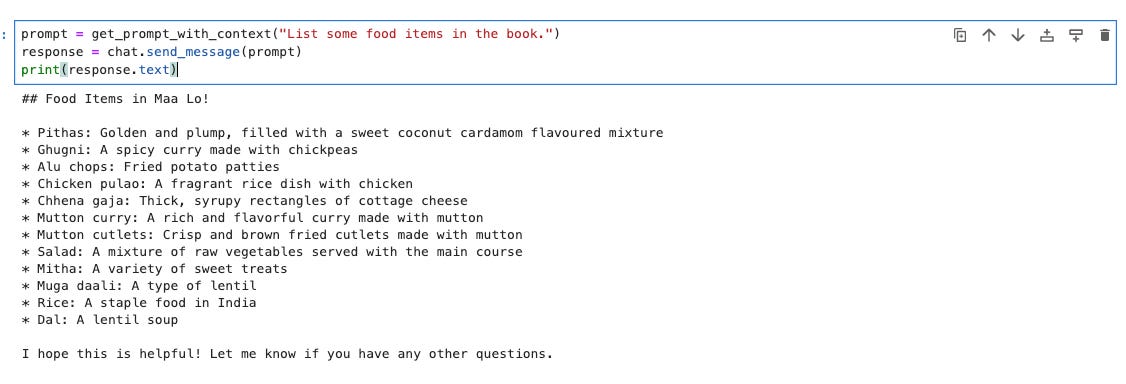
For e.g, find below Gemini answering questions about a regional book!
How to make your search better?
We already have a pretty sophisticated search in under 2 hours of work! But how would make this even better?
Choose the right retrieval mechanism. Depending on the type of content and the complexity of the queries, different techniques can yield better results.
The way you structure your content plays a huge role in improving search. Well-organized data is easier to index and retrieve. Consider using clear headings, paragraphs, and standardized formats to allow for better parsing and indexing by retrieval systems.
Effective chunking is critical for improving search accuracy. Breaking documents into smaller, meaningful segments helps the retrieval system focus on the most relevant pieces of content.
Incorporating metadata into your search strategy adds another layer of refinement.
Finally, improving your embeddings can make your search more nuanced.